
I Tested 5 AI Image Models with the Same 5 Prompts 🧪
A practical AI image model benchmark across 5 distinct capabilities — with real images, honest grades, and clear takeaways.
I had a simple question: which image generation model actually follows instructions? 🤔
Not which one produces the prettiest output. Not which one has the most impressive demo reel. Which one does what you ask, consistently, across different types of challenges.
So I designed a five-prompt benchmark and ran it across five models: black-forest-labs/flux.2-klein-4b, google/gemini-2.5-flash-image (nano banana), bytedance-seed/seedream-4.5, black-forest-labs/flux.2-pro, and x-ai/grok-imagine-image-quality. Same prompts, same grading criteria, no rerolls. 🧪
This is what I found. 🔍
🧭 Why I Built This Benchmark#
Most image model comparisons test the wrong thing.
They ask models to generate a beautiful portrait, a fantasy landscape, or a product shot — and then declare a winner based on aesthetics. But aesthetics are not the bottleneck when you are actually trying to use these tools for real work.
The real bottleneck is instruction compliance. Can the model put the right texture on the right object? Can it understand that a pencil should be inside a mug, not next to it? Can it spell a word correctly on a sign? Can it override its training distribution to draw a bicycle with square wheels because that is what the prompt says?
These are the things that break workflows. These are the things worth testing.
🧪 The Five Tests#
I designed each prompt to stress-test a specific capability.
Test 1 — 🪵 Attribute Bleed.
Three objects on a white background: a textured wooden cube, a translucent blue glass sphere, a metallic gold pyramid.The test is whether textures and materials stay bound to their correct objects, and whether the background stays clean.
Test 2 — 📐 Spatial Reasoning.
A desk scene: red mug on the left corner, a single yellow pencil inside the mug, an open book to the right, a potted plant on the floor under the desk.The test is whether the model understands containment and positional relationships, not just proximity.
Test 3 — 🔤 Typography & Layout.
A storefront with 'STABILITY' above the door, 'OPEN' as a neon sign in the left window, and a coffee cup drawing (no text) in the right window.The test is spelling accuracy, correct placement, and resistance to hallucinating text where there should be none.
Test 4 — ⚙️ Structural Logic.
A technical blueprint of a bicycle with perfectly square wheels, showing a drive chain connecting the rear wheel hub to the foot pedals.The test is whether the model can generate something it has almost certainly never seen in training data.
Test 5 — 🎮 Style Lockdown.
A city intersection at rush hour, rendered as strict 8-bit pixel art with a 16-color palette, visible square pixels, no gradients, no realistic lighting.The test is whether the model maintains style discipline across a complex, detailed scene.
Each test was graded as Pass (1.0), Partial Pass (0.5), or Fail (0.0).
📊 The Results#
Let me go test by test.
🪵 Attribute Bleed#
Four out of five models passed this cleanly. Texture separation is a solved problem for modern models—wood stayed on the cube, glass stayed on the sphere, gold stayed on the pyramid.
The only deduction went to flux.2-pro, which cast soft drop shadows under all three objects. The prompt asked for a pure white background. Shadows are not a pure white background. A minor thing, but constraint compliance is constraint compliance.
grok-imagine-image-quality produced the most convincing wood texture of the five—visible cracks, natural knots, the actual grain of lumber rather than a wallpaper pattern.
| Model | Output |
|---|---|
flux.2-klein-4b |  |
gemini-2.5-flash-image | 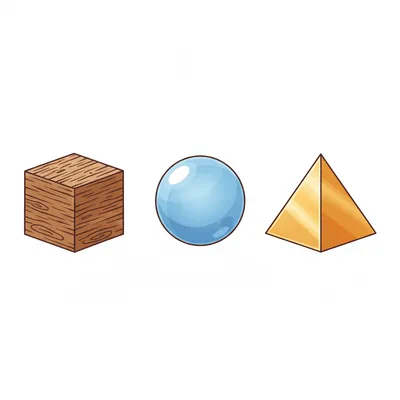 |
seedream-4.5 |  |
flux.2-pro |  |
grok-imagine-image-quality |  |
📐 Spatial Reasoning#
This was the hardest test. Potted plant under the desk? Everyone got that. Broad-scale positional reasoning seems generally reliable.
Pencil inside the mug? This detail proved quite challenging for the models.
Three out of five models (flux.2-klein-4b, gemini-2.5-flash-image, and seedream-4.5) put coffee inside the mug even though it wasn’t mentioned in the prompt.
flux.2-pro was the only successful model here; it managed to place the yellow pencil inside the mug without adding coffee, earning the only full pass of the round.
grok-imagine-image-quality had an interesting failure mode: while it successfully placed the pencil inside the mug, it generated a dark blue circular shadow around the base of the mug on the desk. Not strictly a spatial failure, but exactly the kind of structural flaw that shows up in these relation-heavy renders.
Practical takeaway: if your use case requires precise containment relationships, verify manually. Even though flux.2-pro showed unexpectedly good performance here, models generally are not completely reliable on this yet.
| Model | Output |
|---|---|
flux.2-klein-4b |  |
gemini-2.5-flash-image |  |
seedream-4.5 |  |
flux.2-pro |  |
grok-imagine-image-quality |  |
🔤 Typography & Layout#
Four out of five models spelled “STABILITY” correctly. All five models placed “OPEN” in the left window, and all five left the right window text-free.
flux.2-klein-4b was the only one to fail the main constraint—spelling it “STABLITY” on the main sign. One missing letter. A clean, undeniable typographical error on the most prominent element in the scene.
The good news is that the negative constraint worked across the board. No model hallucinated text in the right window where the prompt explicitly said there should be none. That kind of suppression seems reliable.
Typography has clearly improved in recent model generations. It is no longer the catastrophic failure point it used to be. But “mostly correct” is not the same as “always correct,” and flux.2-klein-4b is a reminder of that.
| Model | Output |
|---|---|
flux.2-klein-4b |  |
gemini-2.5-flash-image |  |
seedream-4.5 |  |
flux.2-pro |  |
grok-imagine-image-quality |  |
⚙️ Structural Logic#
Two out of five models drew circular wheels.
Not roughly circular. Not nearly circular. Perfectly circular, with spokes and all—exactly like a bicycle wheel looks in every training image these models have ever seen.
The prompt said square wheels. Explicitly. With the word “perfectly” in front of it.
flux.2-klein-4b and seedream-4.5 entirely defaulted to the prior. gemini-2.5-flash-image took a different path—while it did manage to draw something resembling squares with rounded corners for the wheels, it also hallucinated a completely meaningless mechanism and nonsensical letters underneath the bicycle. The model lost its structural integrity entirely while trying to break away from its training distribution.
flux.2-pro and grok-imagine-image-quality successfully captured the square wheel form. Their wheels have sharp corners, flat faces, and diagonal structural lines indicating internal geometry.
However, grok-imagine-image-quality’s output has a significant flaw. While it looks like an impressive engineering document at first glance, a closer inspection reveals that the vast majority of the text and dimension callouts consist of illegible, nonsensical symbols. The model succumbed to typographic hallucinations while trying to create a complex blueprint aesthetic. Therefore, it only earns a partial pass.
flux.2-pro shines here. Despite having no text on it, it delivers a clean, structurally accurate drawing, making it the only truly usable option among the candidates for a real-world project.
What this test shows is real. When a prompt asks for something that conflicts with the visual training distribution — something the model has never seen rendered normally — most models default to what they know. The minority that pass are demonstrating something meaningfully different: the ability to construct novel structures from first principles rather than recombining familiar patterns.
| Model | Output |
|---|---|
flux.2-klein-4b |  |
gemini-2.5-flash-image | 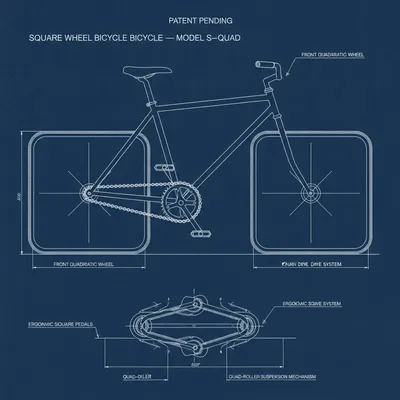 |
seedream-4.5 |  |
flux.2-pro | 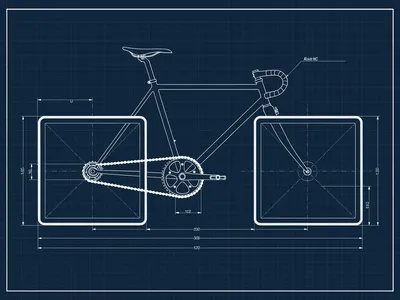 |
grok-imagine-image-quality | 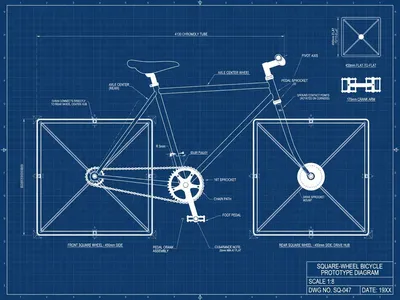 |
🎮 Style Lockdown#
Two models passed, three partially failed.
The divide is stark. gemini-2.5-flash-image and grok-imagine-image-quality maintained hard-edged pixel discipline across the entire canvas—cars, buildings, pedestrians, signs, everything. No anti-aliasing. No gradients. Visible square pixel blocks. A limited flat color palette.
flux.2-klein-4b and seedream-4.5 produced something that looks like pixel art from a distance but falls apart under close inspection. Smooth car edges. Soft shadows. Road gradients. A color palette that clearly never met a 16-color limit. Furthermore, seedream-4.5’s output contains logical errors; if you look closely, there is a person walking on the roof of a building.
flux.2-pro, while generally maintaining the pixel style very well, suffered from bizarre logical hallucinations. There is both a walking person and a car on the roof of a building, plus intertwined cars and people in the traffic below. Even though the visual style is solid, the scene logic collapses, preventing it from earning a full pass.
What is interesting about grok-imagine-image-quality is that it leaned entirely into the diegetic reality of the scene. The signs in the image read “8-BIT BURGERS”, “PIXEL MART”, “MAIN ST / 5TH AVE”. A car has a speech bubble reading “HONK!”. The sky is a single flat color. Every character is the same chunky four-color sprite. The model didn’t just apply a pixel filter to a realistic scene — it generated a scene that is a video game, from the inside.
That is a different kind of style compliance.
| Model | Output |
|---|---|
flux.2-klein-4b |  |
gemini-2.5-flash-image |  |
seedream-4.5 |  |
flux.2-pro |  |
grok-imagine-image-quality |  |
🏁 Final Scores#
flux.2-klein-4b | gemini-2.5-flash-image | seedream-4.5 | flux.2-pro | grok-imagine-image-quality | |
|---|---|---|---|---|---|
| 🪵 Attribute Bleed | ✅ 1.0 | ✅ 1.0 | ✅ 1.0 | ⚠️ 0.5 | ✅ 1.0 |
| 📐 Spatial Reasoning | ⚠️ 0.5 | ⚠️ 0.5 | ⚠️ 0.5 | ✅ 1.0 | ⚠️ 0.5 |
| 🔤 Typography & Layout | ⚠️ 0.5 | ✅ 1.0 | ✅ 1.0 | ✅ 1.0 | ✅ 1.0 |
| ⚙️ Structural Logic | ❌ 0.0 | ❌ 0.0 | ❌ 0.0 | ✅ 1.0 | ⚠️ 0.5 |
| 🎮 Style Lockdown | ⚠️ 0.5 | ✅ 1.0 | ⚠️ 0.5 | ⚠️ 0.5 | ✅ 1.0 |
| Total | 2.5 / 5 | 3.5 / 5 | 3.0 / 5 | 4.0 / 5 | 4.0 / 5 |
flux.2-pro shares the top spot with a 4.0/5. It lost a half-point on the attribute bleed test due to a minor shadow constraint violation, and another half-point in the style lockdown test due to logical scene hallucinations like a car and people on a roof.
grok-imagine-image-quality also shares the top spot with a 4.0/5. Alongside a minor flaw in spatial reasoning, it lost points in the structural logic test by generating nonsensical text on its blueprint.
gemini-2.5-flash-image came in third with a 3.5/5—struggling in spatial reasoning and failing completely in the structural logic test by hallucinating a meaningless structure.
seedream-4.5 scored a 3.0/5. It produced some of the most visually beautiful images in the test—the wireframe bicycle is visually stunning—but visual quality and instruction compliance are independent dimensions, and this test measures the latter.
flux.2-klein-4b finished last with a 2.5/5, suffering a spelling error in typography and a clean failure in structural logic.
💰 Price Comparison#
Performance is only half the story. The other half is cost. Here is how the models stack up on price per generated image:
black-forest-labs/flux.2-klein-4b: $0.014/imageblack-forest-labs/flux.2-pro: $0.03/imagegoogle/gemini-2.5-flash-image(nano banana): $0.04/imagebytedance-seed/seedream-4.5: $0.04/imagex-ai/grok-imagine-image-quality: $0.05/image
The pricing landscape reveals some interesting dynamics. The flux.2-klein-4b model is by far the cheapest, but it also placed last in the benchmark. Its big brother, flux.2-pro, offers a very competitive price at $0.03/image while landing a solid 4.0/5 that ties for the top spot, making it a strong value proposition.
Two of the higher-priced models—gemini-2.5-flash-image and grok-imagine-image-quality—sit at the higher end of the pricing spectrum at $0.04 and $0.05 per image, respectively. While both models show potential, their test results suggest they struggle to fully justify their premium price tags. seedream-4.5 matches the Gemini $0.04 price point, but scored lower on instruction compliance despite its high aesthetic quality.
🧠 What This Actually Means#
A few things that I think matter beyond the numbers.
🌀 The training distribution problem is real. Circular wheels are so deeply embedded in every bicycle image these models have ever processed that “draw a bicycle with square wheels” is not a simple instruction — it is a battle against prior knowledge. Three out of five models lost that battle. This pattern will repeat for anything that looks like a known object but needs to be meaningfully different.
🎨 Aesthetic quality is not the same as utility. seedream-4.5’s wireframe bicycle is the most beautiful image in the structural logic test. It is also a complete failure of the test. If you are evaluating models for real work, run the prompts from your actual use case, not the ones that produce impressive portfolio pieces.
📐 Spatial containment is a challenging detail. Most models struggled with the “pencil inside mug” detail, defaulting to familiar patterns and adding coffee to the mug. This matters for anyone trying to generate accurate spatial diagrams, instructional illustrations, or scenes where object relationships are semantically meaningful.
📏 The gap between first and last place is large. 2.5 versus 4.0 out of 5 is not a marginal difference. The models at the top of this benchmark are doing something meaningfully different from the models at the bottom.
🔁 The Benchmark Is Reusable#
These five prompts are designed to be reproducible. If you want to run the same tests on a different model, the prompts are exactly as described above, and the grading criteria are explicit.
Run them. Compare the results. Share what you find. 🌍
That is the kind of knowledge that becomes more useful when it is shared. 🤝